AlJazeera (3.170)
Der bekannte TV-Sender AlJazeera hat jetzt (endlich?) seinen eigenen Channel bei YouTube. Wenn man bedenkt was man sonst so für Material von diesem Sender zugespielt bekommt, kann man sich ja denken wo die nächsten Terror-Drohungen veröffentlicht werden...
Monat: April 2007
Gestern haben Google und Clear Channel Communications eine enge Kooperation angekündigt. Google wird in nächster Zeit 5% der Werbezeiten von Clear Channels 1.200 Radiostationen über seine Audio Ads verkaufen. Noch vor einigen Monaten stand sogar ein Übernahmegerücht von Clear Channel im Raum. Mit der Kooperation kontrolliert Google schon auf einen Schlag einen nicht zu verachtenden Teil des US-Radiomarktes. Clear Channel ist mit weitem Abstand das größte Radionetzwerk in den USA. 675 Radiostationen werden ab sofort ihre Werbespots durch die Audio Ads bekommen, die anderen dürften bei erfolgreichem Test wohl auch noch folgen. » Ankündigung im Google-Blog » Pressemeldung von Google
Spätestens seit der Präsentation von Microsofts neuer Suchmaschine Live.com wird das Thema "Infinite Scrolling" (Scrolling ohne Ende) bei einigen neueren Diensten ganz groß geschrieben. Dass dieses Thema auch bei Google angekommen ist zeigt z.B. der Google Reader. Für alle die dieses Feature bisher in der Websuche vermisst haben gibt es jetzt ein kleines Greasemonkey-Script.
Der Sinn und Zweck von Infinite Scrolling ist, dass man keine neue Seite laden muss um an die nächsten Informationen zu kommen. Damit aber nicht bei jeder Suchabfrage tausende Zeilen angezeigt werden müssen obwohl nur die ersten 3-4 interessant sind, wird dieser Content dynamisch nachgeladen. Ein aktuelles Beispiel für Infinite Scrolling ist neben dem Google Reader die Bildersuche von Live.com. Das Greasemonkey-Script "Infinite Scrolling" erkennt automatisch wenn man sich dem Ende der Suchergebnis-Seite nähert und lädt dann automatisch die nächste Seite nach und zeigt diese unter der aktuellen an. Dabei ist es völlig egal ob man sich 10, 20, 50 oder 100 Suchergebnisse pro Seite anzeigen lässt. Da Googles Websuche bekanntermaßen eine traumhafte Ladezeit hat merkt man überhaupt nicht dass hier etwas dynamisch nachgeladen wird und es kann in hohem Tempo durch tausende Ergebnisse navigiert werden. Wirklich ein sehr gutes PlugIn, zwar etwas gewöhnungsbedürftig dass jetzt keine einzelnen Seiten mehr angezeigt werden, aber wesentlich komfortabler ;-) Ich werde es erstmal eine zeit lang installiert lassen. » Script Infinite Scrolling installieren [Google OS]
Nach Mountain View und Irland hat Google jetzt sein drittes Hauptquartier in Buenos Aires, Argentinien eröffnet. Es gibt zwar weltweit Niederlassungen, aber nur diese 3 sind am operativen Geschäft in ihrer Region beschäftigt. Das neue Hauptquartier beherbergt zur Zeit 1.000 Googler, bis zu 3.000 könnten es aber noch werden... Die Niederlassung wird sich um das gesamte latein-amerikanische Geschäft kümmern, was auch teilweise den europäischen Kontinent - insbesondere Spanien - mit einschließt. Für den Rest von Europa ist auch weiterhin die Niederlassung in Irland verantwortlich. Die 2.000 Google die hier in der Zukunft noch zusätzlich beschäftigt werden sollen werden übrigens noch gesucht - also viel Erfolg bei der Jobsuche ;-) Zur Eröffnung war natürlich auch Big Boss Eric Schmidt anwesend und hat eine kleine Ansprache gehalten: [Googlified]
Benedikt XVI (3.053)
Na dann alles gute zum 80. Papa Ratzi ;-)
 Google übernimmt, wie bereits vor einigen Tagen vermutet wurde für 3,1 Milliarden US-Dollar das Online Werbeunternehmen DoubleClick. "Damit soll sich Google schneller am Markt durchsetzen", erklärt Google-Chef Eric Schmidt. Auch Microsoft, AOL und Yahoo hatten sich für das Unternehmen interessiert.
DoubleClick ist weitweiter Marktführer im Bereich Online-Werbung, betreibt unter anderem AdServer für zahlreiche Webseiten und nahm im Jahr 2006 etwa 300 Millionen US-Dollar ein.
Google Gründer Sergey Brin zu der Übernahme: "Es war immer unser Ziel Online-Werbung besser zu machen - weniger aufdringlich, effektiver und nützlicher. Zusammen mit DoubleClick wird Google das Internet für Nutzer, Werbtreibende und Website-Betreiber effizienter machen." DoubleClick beschäftigt an 17 Standorten weltweit insgesamt 1200 Mitarbeiter, die nun neue Googler werden.
Hauptprofiteur des Deals sind aber vor allem der Finanzinvestor Hellman & Friedman sowie JMI Equity und das DoubleClick-Management. Hellman & Friedman hatte erst Mitte 2005 einen Mehrheitsanteil an DoubleClick für 1,1 Milliarden Dollar gekauft. Dementsprechend verkündet der DeoubleClick CEO David Rosenblatt: "Google ist für uns der perfekte Partner. DoubleClick's Lösungen für Medienkunden und Anbieter mit der Skalierbarkeit und Innovationsfreude von Google bringen einen ungeheuren Vorteil für unsere Mitarbeiter und Kunden."
Die Verwaltungsräte beider Unternehmen haben der Transaktion bereits zugestimmt. Doch erst bis zum Jahresende soll der Mega-Deal abgewickelt werden. Wir auch anders, auch Google schüttelt bei so viel Investitionen nicht einfach mal innerhalb von Tagen und Wochen Milliarden aus dem Ärmel.
Immerhin aquirierte Google erst vor einem halben Jahr aquirierte das Videoportal YouTube für eine StatUp-unübliche Rekordsumme von 1,65 Milliarden US-Dollar. Dies war die bisher größte Übernahme des Suchgiganten, die mit dem heutigen Deal in den Schatten gestellt wurde.
Offizielle Pressemitteilung von Google zur DoubleClick Aquisition
UPDATE: Meldung auf dem offiziellen Google Blog
Offizielles FAQ zur Übernahme zum PDF Download
[Google Blogscoped, Golem.de, Spiegel Online, ZDNet, Googlified]
Google übernimmt, wie bereits vor einigen Tagen vermutet wurde für 3,1 Milliarden US-Dollar das Online Werbeunternehmen DoubleClick. "Damit soll sich Google schneller am Markt durchsetzen", erklärt Google-Chef Eric Schmidt. Auch Microsoft, AOL und Yahoo hatten sich für das Unternehmen interessiert.
DoubleClick ist weitweiter Marktführer im Bereich Online-Werbung, betreibt unter anderem AdServer für zahlreiche Webseiten und nahm im Jahr 2006 etwa 300 Millionen US-Dollar ein.
Google Gründer Sergey Brin zu der Übernahme: "Es war immer unser Ziel Online-Werbung besser zu machen - weniger aufdringlich, effektiver und nützlicher. Zusammen mit DoubleClick wird Google das Internet für Nutzer, Werbtreibende und Website-Betreiber effizienter machen." DoubleClick beschäftigt an 17 Standorten weltweit insgesamt 1200 Mitarbeiter, die nun neue Googler werden.
Hauptprofiteur des Deals sind aber vor allem der Finanzinvestor Hellman & Friedman sowie JMI Equity und das DoubleClick-Management. Hellman & Friedman hatte erst Mitte 2005 einen Mehrheitsanteil an DoubleClick für 1,1 Milliarden Dollar gekauft. Dementsprechend verkündet der DeoubleClick CEO David Rosenblatt: "Google ist für uns der perfekte Partner. DoubleClick's Lösungen für Medienkunden und Anbieter mit der Skalierbarkeit und Innovationsfreude von Google bringen einen ungeheuren Vorteil für unsere Mitarbeiter und Kunden."
Die Verwaltungsräte beider Unternehmen haben der Transaktion bereits zugestimmt. Doch erst bis zum Jahresende soll der Mega-Deal abgewickelt werden. Wir auch anders, auch Google schüttelt bei so viel Investitionen nicht einfach mal innerhalb von Tagen und Wochen Milliarden aus dem Ärmel.
Immerhin aquirierte Google erst vor einem halben Jahr aquirierte das Videoportal YouTube für eine StatUp-unübliche Rekordsumme von 1,65 Milliarden US-Dollar. Dies war die bisher größte Übernahme des Suchgiganten, die mit dem heutigen Deal in den Schatten gestellt wurde.
Offizielle Pressemitteilung von Google zur DoubleClick Aquisition
UPDATE: Meldung auf dem offiziellen Google Blog
Offizielles FAQ zur Übernahme zum PDF Download
[Google Blogscoped, Golem.de, Spiegel Online, ZDNet, Googlified]

Einige von euch werden sich sicherlich schon einmal eine Gegend mit den Google Maps angesehen haben und wollten diese dann mit Google Earth weiter unter die Lupe nehmen, etwa wegen Ortsinformationen, 3D-Gebäuden, Landschaftsdetails & co. Das Problem, wie bekomme ich in möglichst wenig Schritten in Earth zum gleichen Ort, kann mit ein wenig JavaScript oder Greasemonkey ganz einfach gelöst werden. IOnut von Google OS hat einige Möglichkeiten in seinem Blog zusammengetragen um in Earth die gleiche Ansicht wie aktuell bei den Maps zu bekommen: Parameter kopieren » Einmal auf "Link to this Page" klicken, den Parameter "ll=" kopieren und bei Google Earth in das Suchfeld eintragen. So habe ich es bisher gemacht, aufwendig - aber funktioniert. KML-Output » Einfach wieder auf "Link to this Page" klicken und dann anschließend "&output=kml" an die URL anhängen, kurz danach öffnet sich ein Download-Fenster für eine KML-Datei und kurz danach Google Earth. JavaScript-Bookmarklet » Den Button einfach irgendwo in die Browser-Toolbar ziehen oder in den Bookmarks speichern. Ein Klick auf den Button und die aktuelle Maps-Ansicht öffnet sich in Earth - funktioniert in jedem Browser. View in Google Earth Greasemonkey » Um sich als Firefox-User den obigen Button auch noch zu sparen gibt es auch noch ein Greasemonkey-Script das den Button direkt über die Karte setzt. Direkt über der Karte erscheint der Link "View in Google Earth" und öffnet genauso wie die 2 vorherigen Tipps einen KML-Download und kurz darauf Google Earth. -- Ich habe mich für das Greasemonkey-Script und den Bookmark-Button entschieden, ich nutze ja leider immer noch mehrere Browser. Ich bin gespannt wann Google diese Lücke selbst einmal schließen wird und so einen Button in die Maps einbauen wird. IOnut hat das Team, dass seinen Blog liest, sicherlich auf eine gute Idee gebracht ;-) [Google OS]
Hölle (-)
Wer hätte dass gedacht, die Hölle liegt mitten in Deutschland... Aber auch andere Länder haben sich ihre eigene kleine Hölle eingerichtet ;-)
 Die Google Bezahlanwendung kommt über den Atlantik. Auch in Großbritannien können nun Online-Shops Google Checkout nutzen. Da läßt sich sich vermuten, dass der Start dieses Dienstes in Deutschland nicht mehr lange auf sich warten läßt.
Von jetzt bis 2008 können die Onlie-Shops die Checkout einsetzen diesen Dienst kostenlos nutzen. Für bestellungen über 30 Pfund ginbt es sogar für jeden Erstkunden 10 Pfund geschenkt.
[Official Google Blog]
Die Google Bezahlanwendung kommt über den Atlantik. Auch in Großbritannien können nun Online-Shops Google Checkout nutzen. Da läßt sich sich vermuten, dass der Start dieses Dienstes in Deutschland nicht mehr lange auf sich warten läßt.
Von jetzt bis 2008 können die Onlie-Shops die Checkout einsetzen diesen Dienst kostenlos nutzen. Für bestellungen über 30 Pfund ginbt es sogar für jeden Erstkunden 10 Pfund geschenkt.
[Official Google Blog]
Als vor 2 Monaten die ersten 3D-Gebäude auf den Google Maps aufgetaucht sind haben wir gedacht dass die 3D-Funktionalität einer 2D-Anwendung damit ausgereizt ist. Dass die Darstellung der Gebäude aber noch sehr viel mehr ins Detail gehen kann zeigen die Maps jetzt in der neuesten Version die beinahe schon mit richtigen 3D-Gebäuden aufwarten kann. Aktuelle 3D-Darstellung:
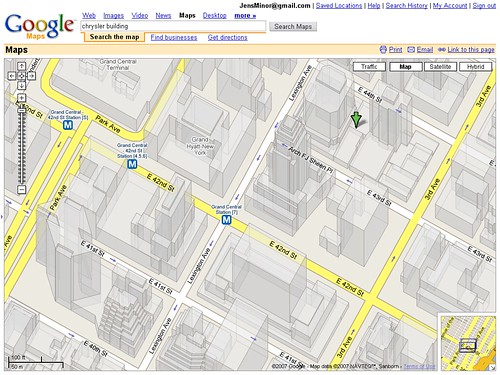
Vorherige 3D-Darstellung:
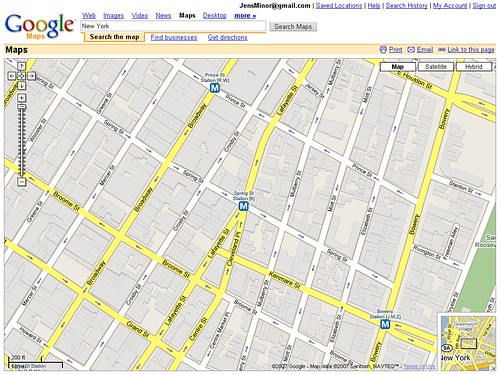
Ich denke der Unterschied zur vorherigen Version ist deutlich erkennbar. In der allerersten Maps-Version mit Gebäuden wurden diese als graue Kästen eingezeichnet. In einer nächsten Version wurden diese grauen Kästen um einen kleinen 3D-Effekt erweitert, der aber nicht wirklich auf die Gebäudeform schließen lässt. Die aktuelle Version zeigt nicht mehr nur hässliche 3D-Vierecke an sondern lässt richtige Strukturen, Höhenunterschiede und Formen der Gebäude deutlich erkennen. Die Daten für diese Gebäude kommen von Google Earth, bei dem die Darstellung der Gebäude in den ersten Versionen fast genauso aussah wie heute bei den Maps. Mittlerweile bietet Earth fotorealistische Gebäude und die grauen Klötze wandern in Maps. Bleibt nur abzuwarten wann die ersten Foto-Gebäude auch bei den Maps erscheinen werden - ich denke bis dahin wird es garnicht mehr so lange dauern. Die neuen Gebäude sind jetzt zwar sehr nett anzusehen und beeindruckend, aber ich denke es ist auch ein großer Rückschritt in Sachen Usability. Gerade bei Großstädten mit Wolkenkratzern sind die Straßen kaum noch ohne größere Mühe zu erkennen. Mittlerweile ist es fast so als wenn man mit aktivierten 3D-Gebäude in New York versucht einen Weg zu finden - unmöglich. Nur leider können diese Gebäude bei den Maps nicht abgeschaltet werden... Ein zuschaltbarer Layer für Informationen auf den Maps muss endlich her. Genau wie bei den Verkehrsinfos sollten auch Gebäude, U-Bahn-Stationen und weitere Informationen die auf einem "normalen" Stadtplan nichts verloren haben optional sein und nicht standardmäßig angezeigt werden. » Häuserdschungel von Manhattan [Google OS]

Seit August des letzten Jahres finanziert Google die Weiterentwicklung der Texterkennung Tesseract. Mittlerweile wurde das Projekt in OCRopus umbenannt und kann erste Erfolge vorweisen: Im 3. Quartal diesen Jahres soll die erste offizielle Alpha-Version erscheinen, auf die endgültige Version mit grafischer Oberfläche müssen wir allerdings noch über 1,5 Jahre warten. Das Projekt OCRopus wird derzeit im Auftrag von Google am Deutschen Forschungszentrum für künstliche Intelligenz entwickelt und mit englischen Texten gefüttert. Um eine nahezu 100%ige Trefferquote zu erreichen gleicht das Tool die erkannten Texte mit riesigen Datenbanken ab und kann so von selbst erkennen ob der erkannte Text Sinn macht oder lieber noch ein Erkennungsvorgang gestartet werden sollte. Aus diesem Grund funktioniert das Tool zur Zeit auch nur mit englischen Texten. Die erste Alpha-Version wurde für das 3. Quartal diesen Jahres angekündigt, die Beta-Version soll anfang 2008 erscheinen und die erste endgültige Version mit einer grafischen Benutzeroberfläche dürfen wir nicht vor dem 3. Quartal 2008 erwarten. Ich bin gespannt wie Google das fertige Script dann für sich nutzen wird und ob es wirklich eine 100%ige Erkennungsrate haben soll. » Projekt OCRopus » Ankündigung im Code-Blog [heise]

Für den jährlich stattfindenden Summer of Code-Wettbewerb haben die Googler jetzt auch einen eigenen Blog erstellt. Das Eröffnungsposting kann gleich mit der guten Nachricht aufwarten dass statt 600 in diesem Jahr 900 Personen an dem Wettbewerb teilnehmen können. Weiteren 6.200 Bewerbern musste leider abgesagt werden. Ich denke in diesem Jahr wird der Wettbewerb, nicht zuletzt durch den Blog, sehr viel mehr Aufmerksamkeit auf sich ziehen - ich bin gespannt was dabei herauskommt. » Google Summer of Code-Blog » Ankündigung im Code-Blog » Liste der Google-Blogs
 Zum Jahestag des ersten Raumflugs in der Geschichte der Menschheit am 12. April 1961 hat Google heute ein entsprechendes Doodle zum Gedenken an Yuri Gagarin geschaltet. Der sowjetische Kosmonaut Juri Alexejewitsch Gagarin lebte von 1934 bis 1968 und war der erste Mensch im Weltall. In 108 Minuten umrundete er mit der Raumkapsel Wostok 1 zum ersten mal unseren Planeten.
Zum Jahestag des ersten Raumflugs in der Geschichte der Menschheit am 12. April 1961 hat Google heute ein entsprechendes Doodle zum Gedenken an Yuri Gagarin geschaltet. Der sowjetische Kosmonaut Juri Alexejewitsch Gagarin lebte von 1934 bis 1968 und war der erste Mensch im Weltall. In 108 Minuten umrundete er mit der Raumkapsel Wostok 1 zum ersten mal unseren Planeten.
Gemeinsam mit dem Holocaust Museum in Washington hat Google ein Projekt gestartet um den seit Jahren anhaltenden Konflikt in Darfur in das Bewusstsein der Menschen zu rufen. Ein Layer für Google Earth über dieser Region zeigt die Anzahl der zerstörten Dörfer, der Flüchtlinge und Fotos sowie Videos aus der Region. Erschreckend und sehenswert zugleich.
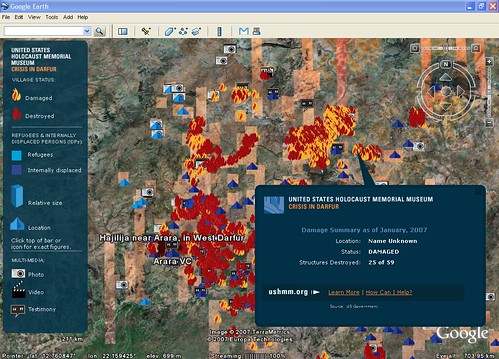
Seit dem Jahr 2003 tobt im Sudan ein (Klein-)Krieg von dem die Welt bisher nicht wirklich Kenntnis genommen hat und so natürlich auch die Unterstützung von anderen Ländern zu Wünschen übrig lässt. Schätzungen zufolgen sind bisher 200.000 bis 400.000 Menschen bei den Kämpfen und Zerstörungszügen ums Leben gekommen, mehr als 2,5 Mio. Menschen sind auf der Flucht. Um die Augen der Welt auf diese Region zu richten und ihr ein Bild von den Ausmaßen zu geben zeigt der Earth-Layer eine Sammlung aller Kriegsschauplätze mit weiteren Informationen und medialen Inhalten. Für eine bessere Übersicht wird praktischerweise gleich eine Legende mitgeliefert die die Symbole genau erklärt. » KMZ-Datei downloaden » Presseerklärung von Google [thx to: Gregor Best]
Die Sitemaps, die mittlerweile von immer mehr Suchmaschinen unterstützt werden, helfen nicht nur den Suchmaschinen das Internet besser zu verstehen sondern sind auch aus SEO-technischer Sicht sehr praktisch. Damit die Suchmaschinen diese auch finden kann die Sitemap-URL jetzt direkt via robots.txt übergeben werden. Außerdem ist jetzt auch ask.com mit im Boot. Bisher musste eine Sitemap auf Sitemaps.org oder über die jeweiligen Portale der Suchmaschinen eingestellt werden. Das ist natürlich nicht ganz so praktisch und musste dringend verbessert werden. Ab sofort muss die URL der Sitemap nur noch in die eigene robots.txt mit folgender Zeile eingetragen werden:
Sitemap: http://www.mysite.com/sitemap.xmlLaut dem Webmaster-Blog sollte man dennoch zusätzlich die Sitemap via den Portalen übermitteln, aber warum wird nicht genau angegeben. Unterstützt werden die Sitemaps derzeit von Google, Yahoo!, MSN und Ask und einigen weiteren kleinen Suchmaschinen die nicht näher genannt werden. Ich denke damit sind die Sitemaps jetzt endgültig ein unverzichtbares SEO-Tool und sollten von jedem Webmaster angelegt werden. » Ankündigung im Webmaster-Blog