Schlagwort: google-research
 Das Google Research-Team hat mal wieder ein sehr interessante Tool veröffentlicht: Die Abteilung Spracherkennung scheint mittlerweile so sehr auf die eigene Technologie zu vertrauen, dass man jetzt ein Gadget für iGoogle veröffentlicht hat mit dem die Videos aller US-Präsidentschaftskandidaten nach einzelnen Wörtern durchsucht werden können.
Das Google Research-Team hat mal wieder ein sehr interessante Tool veröffentlicht: Die Abteilung Spracherkennung scheint mittlerweile so sehr auf die eigene Technologie zu vertrauen, dass man jetzt ein Gadget für iGoogle veröffentlicht hat mit dem die Videos aller US-Präsidentschaftskandidaten nach einzelnen Wörtern durchsucht werden können.
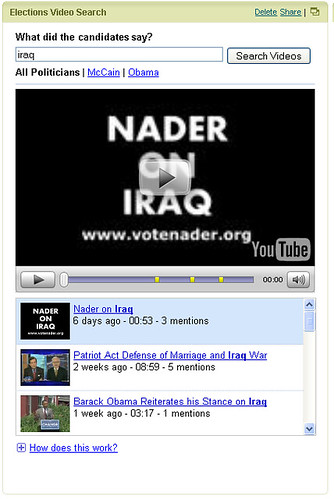
Das Gadget ist ganz einfach zu bedienen: Einfach das gewünschte Wort einzugeben und eventuell noch auswählen ob nur Videos von Obama oder McCain oder aller Kandidaten durchsucht werden soll. Am unteren Ende des Gadgets wird eine Liste mit Videos angezeigt in denen die Wörter vorkommen. Spielt man das Video ab, kann man direkt zu der Stelle springen an dem das Wort fällt. Die entsprechende Position ist im Video gelb markiert. Zum Startschuss des großangelegten Tests werden nur Videos der Präsidentschaftskandidaten auf YouTube, oder YouChoose durchsucht. Google gibt zwar an, dass das ganze vielleicht nicht 100%ig zuverlässig funktioniert, aber scheint sich doch so sicher zu sein, das ganze bei einem doch relativ wichtigen Thema auszuprobieren und auch das Beta-Label sucht man in diesem Fall vergeblich. Getestet und trainiert wurde die Spracherkennung schon seit langer Zeit mit Goog-411. Durch dieses Angebot hat Google nahezu jeden Dialekt und Stimmlage und auch verschiedene Aussprachen bereits aufgenommen und untersucht. Ich denke wenn das ganze jetzt bei Obama & Co. gut funktioniert, könnte man dieses Feature demnächst auch standardmäßig bei YouTube finden. Sicherlich wird es eine ganze Zeit lang dauern _alle_ Videos bei YouTube nach bestimmten Texten und Wörtern zu durchsuchen und entsprechend zu indizieren, aber ich könnte wetten dass das YouTube-Team bereits damit begonnen hat. Wenn die Spracherkennung wirklich reibungslos funktioniert ist das doch mal wieder eine schöne Innovation mit der Tags & Co. praktisch schon überflüssig werden - wenn entsprechend viel im Video gesprochen wird. » Gadget zu iGoogle hinzufügen » Ankündigung im Google-Blog
 Der Leiter von Google Research, Peter Norvig, hat auf der "Emerging Technology"-Konferenz in San Diego einen Einblick in Googles Such- und Übersetzungstechnologie gegeben.
Aus diesem ergibt sich, dass das Unternehmen nicht nur auf komplizierte Modelle und Theorien setzt, sondern vor allem auch auf eine sehr große Menge an Daten. Bei der Übersetzung von Chinesisch-Englisch erklärt sich das am besten: Im Chinesischem bilden mehrere Schriftzeichen ein Wort, aber ein Schriftzeichen bedeutet gleichzeitig auch ein anderes bzw. eine andere Silbe.
Um halbwegs sinnvolle Chinesisch-Englisch Übersetzungen zu liefern, werde bei der Übersetzung Vergleichsdaten - Wahrscheinlichkeitstabellen - untersucht. Dann wird bei der Übersetzung eines Textes mit diesen Tabellen verglichen.
Sehr ähnlich ist es bei der Bildersuche. Bisher wurden nur die Metadaten eines Fotos verwendet. Das ergab eine hoche Fehlerquote. In Zukunft will man die ersten 1 000 Bilder der Ergebnisse vergleichen und dann Ähnlichkeiten feststellen. Haben zwei Bilder viele Punkte gemeinsam werde sie als ähnlich und damit relevant eingestuft.
Laut Norvig ist die Datenmenge das Problem der Start-ups. Google habe durch große Serverfarmen genügend Speicher um solche Tabellen anzulegen.
[Winfuture]
Der Leiter von Google Research, Peter Norvig, hat auf der "Emerging Technology"-Konferenz in San Diego einen Einblick in Googles Such- und Übersetzungstechnologie gegeben.
Aus diesem ergibt sich, dass das Unternehmen nicht nur auf komplizierte Modelle und Theorien setzt, sondern vor allem auch auf eine sehr große Menge an Daten. Bei der Übersetzung von Chinesisch-Englisch erklärt sich das am besten: Im Chinesischem bilden mehrere Schriftzeichen ein Wort, aber ein Schriftzeichen bedeutet gleichzeitig auch ein anderes bzw. eine andere Silbe.
Um halbwegs sinnvolle Chinesisch-Englisch Übersetzungen zu liefern, werde bei der Übersetzung Vergleichsdaten - Wahrscheinlichkeitstabellen - untersucht. Dann wird bei der Übersetzung eines Textes mit diesen Tabellen verglichen.
Sehr ähnlich ist es bei der Bildersuche. Bisher wurden nur die Metadaten eines Fotos verwendet. Das ergab eine hoche Fehlerquote. In Zukunft will man die ersten 1 000 Bilder der Ergebnisse vergleichen und dann Ähnlichkeiten feststellen. Haben zwei Bilder viele Punkte gemeinsam werde sie als ähnlich und damit relevant eingestuft.
Laut Norvig ist die Datenmenge das Problem der Start-ups. Google habe durch große Serverfarmen genügend Speicher um solche Tabellen anzulegen.
[Winfuture]
 Laut einer aktuellen Studie von Google Research nimmt die Verbreitung von Würmern, Trojanern und ähnlicher Schadsoftware über das Internet immer mehr zu - und das nur wegen längst bekannter Sicherheitslücken. Millionen von Webseiten und eMail-Servern tragen unwissentlich zur Verbreitung solcher Software oder Spam-Mails bei ohne es zu wissen. Das schlägt sich natürlich auch auf Googles Suchergebnisse nieder: In jeder hundertsten Websuche findet sich mindestens ein Link zu einer solchen Seite wieder.
Besonders chinesische Webmaster machen sich nicht all zu viele Gedanken um ihre Sicherheitssysteme und betreiben somit ein Paradies für solche Schadsoftware. 67% aller Schadsoftware wird in China gehostet und wird zu 64% über chinesische Seiten vertrieben. Auf Platz 2 folgt die USA mit je 15% in beiden Bereichen. Deutschland hält sich mit 1% Hosting und 2% Verbreitung aber auch in den Top10.
Mehr als 38% aller infizierten Server nutzen veraltetete Software von Apache bzw. eine alte PHP-Version mit Sicherheitslücken. Durch ein einfaches Updates könnte das ganze unterbunden werden - aber anscheinend interessieren solche Studien niemanden. Viele Webseiten verbreiten Schadsoftware oder zumindest Links dazu unwissentlich durch von Hackern eingebaute iFrames die niemandem einfallen. Das liegt teils an unsicherer Software, teils an 123abc-Passwörtern und teilweise natürlich auch an Webseiten die jeden HTML-Code ungeprüft von ihren Usern annehmen und veröffentlichen.
Mittlerweile finden sich bei 1% aller Suchergebnisseiten mindestens ein Link zu einer Seite die Schadsoftware verbreitet oder zumindest verlinkt. Der Trend ist leider sehr stark ansteigend, in den letzten 10 Monaten hat sich diese Zahl verdreifacht.
Google kann gegen die eigentliche Verbreitung nicht viel tun, ist aber immerhin darum bemüht Links zu solchen Seiten entweder nicht im Index zu führen oder den Besucher vor dem aufrufen der Seite zu warnen. Wenn aber immer mehr Seiten zur Verbreitung beitragen muss bald vor dem Besuch des halben Webs gewarnt werden... Grund genug für alle Chinesen endlich ihre Software upzudaten ;-)
» Studie von Google [PDF]
[heise]
Zur Zeit besteht die Seite Google Research nur aus einer Reihe von Informationen rund um Googles Forschungsabteilung und dessen Ergebnisse bzw. Publikationen. Aber natürlich betreiben auch viele andere Unternehmen, Universitäten und freie Wissenschaftler Forschung - ohne dass die große Masse darauf Zugriff hat. Das möchte Google jetzt ändern und wird in den nächsten Tagen eine eigene, offene, Forscher-Datenbank aufbauen.
Laut Informationen von internen Google-Quellen wird das neue Portal direkt unter der Adresse research.google.com erreichbar sein und jedem Wissenschaftler und Forscher die Möglichkeit geben seine Ergebnisse zu veröffentlichen. Die dort eingestellten Daten können dann von der ganzen Welt durchsucht, angesehen und auch ausgewertet werden. Für die Auswertung steht der Trendalyzer, den Google vor knapp 1 Jahr übernommen hat, bereit. Für die ansprechende Präsentation der eingestellten Daten ist also schon einmal gesorgt.
Der Speicherplatz zur Veröffentlichung der eigenen Forschungsdaten soll übrigens unbegrenzt zur Verfügung stehen. Von einem wenige-KB-Textdokument über Gigabyte-Videos bis hin zu Fotoserien und Datenströmen die die TB-Grenze durchbrechen soll alles möglich sein. Erstere wird man noch über ein Web-Interface hochladen können, aber um einige TB an Daten auf die Plattform zu bringen hat Google eine eher herkömmliche Methode:
Wer eine große Datenmenge in das Portal laden möchte, muss sich bei Google registrieren und bekommt dann einen kleinen Festplatten-Tower mit einer Speicherkapazität von 3 TB zugeschickt. Auf dieses Speichermedium kann der Wissenschaftler dann seine Daten kopieren und an Google zurück zu senden - Google sorgt dann dafür dass die Daten innerhalb kürzester Zeit öffentlich verfügbar sind. Die dazugehörige Technik ist ebenfalls, wie der Trendalyzer, seit März 2007 vorhanden.
Der Starttermin für dieses Projekt lag in der letzten Woche, Google Research ist also längst überfällig und kann jeder Zeit an den Start gehen. Zum Start soll Google das Portal auch selbst schon mit interessanten Daten gefüttert haben - so soll etwa alleine vom Hubble-Teleskop Bildmaterial mit einer Größe von 120 TB (!) zur Verfügung stehen. Ich denke das Portal könnte, insbesondere in Verbindung mit dem Trendalyzer, ein schönes Spielzeug werden und die Hobby-Forschung fördern ;-)
P.S. Bisher handelt es sich, wie bei Google üblich, nur um ein Gerücht - aber ich halte es für sehr realistisch.
Hier noch eine Präsentation zu Google Research vom Mai 2007:
Laut einer aktuellen Studie von Google Research nimmt die Verbreitung von Würmern, Trojanern und ähnlicher Schadsoftware über das Internet immer mehr zu - und das nur wegen längst bekannter Sicherheitslücken. Millionen von Webseiten und eMail-Servern tragen unwissentlich zur Verbreitung solcher Software oder Spam-Mails bei ohne es zu wissen. Das schlägt sich natürlich auch auf Googles Suchergebnisse nieder: In jeder hundertsten Websuche findet sich mindestens ein Link zu einer solchen Seite wieder.
Besonders chinesische Webmaster machen sich nicht all zu viele Gedanken um ihre Sicherheitssysteme und betreiben somit ein Paradies für solche Schadsoftware. 67% aller Schadsoftware wird in China gehostet und wird zu 64% über chinesische Seiten vertrieben. Auf Platz 2 folgt die USA mit je 15% in beiden Bereichen. Deutschland hält sich mit 1% Hosting und 2% Verbreitung aber auch in den Top10.
Mehr als 38% aller infizierten Server nutzen veraltetete Software von Apache bzw. eine alte PHP-Version mit Sicherheitslücken. Durch ein einfaches Updates könnte das ganze unterbunden werden - aber anscheinend interessieren solche Studien niemanden. Viele Webseiten verbreiten Schadsoftware oder zumindest Links dazu unwissentlich durch von Hackern eingebaute iFrames die niemandem einfallen. Das liegt teils an unsicherer Software, teils an 123abc-Passwörtern und teilweise natürlich auch an Webseiten die jeden HTML-Code ungeprüft von ihren Usern annehmen und veröffentlichen.
Mittlerweile finden sich bei 1% aller Suchergebnisseiten mindestens ein Link zu einer Seite die Schadsoftware verbreitet oder zumindest verlinkt. Der Trend ist leider sehr stark ansteigend, in den letzten 10 Monaten hat sich diese Zahl verdreifacht.
Google kann gegen die eigentliche Verbreitung nicht viel tun, ist aber immerhin darum bemüht Links zu solchen Seiten entweder nicht im Index zu führen oder den Besucher vor dem aufrufen der Seite zu warnen. Wenn aber immer mehr Seiten zur Verbreitung beitragen muss bald vor dem Besuch des halben Webs gewarnt werden... Grund genug für alle Chinesen endlich ihre Software upzudaten ;-)
» Studie von Google [PDF]
[heise]
Zur Zeit besteht die Seite Google Research nur aus einer Reihe von Informationen rund um Googles Forschungsabteilung und dessen Ergebnisse bzw. Publikationen. Aber natürlich betreiben auch viele andere Unternehmen, Universitäten und freie Wissenschaftler Forschung - ohne dass die große Masse darauf Zugriff hat. Das möchte Google jetzt ändern und wird in den nächsten Tagen eine eigene, offene, Forscher-Datenbank aufbauen.
Laut Informationen von internen Google-Quellen wird das neue Portal direkt unter der Adresse research.google.com erreichbar sein und jedem Wissenschaftler und Forscher die Möglichkeit geben seine Ergebnisse zu veröffentlichen. Die dort eingestellten Daten können dann von der ganzen Welt durchsucht, angesehen und auch ausgewertet werden. Für die Auswertung steht der Trendalyzer, den Google vor knapp 1 Jahr übernommen hat, bereit. Für die ansprechende Präsentation der eingestellten Daten ist also schon einmal gesorgt.
Der Speicherplatz zur Veröffentlichung der eigenen Forschungsdaten soll übrigens unbegrenzt zur Verfügung stehen. Von einem wenige-KB-Textdokument über Gigabyte-Videos bis hin zu Fotoserien und Datenströmen die die TB-Grenze durchbrechen soll alles möglich sein. Erstere wird man noch über ein Web-Interface hochladen können, aber um einige TB an Daten auf die Plattform zu bringen hat Google eine eher herkömmliche Methode:
Wer eine große Datenmenge in das Portal laden möchte, muss sich bei Google registrieren und bekommt dann einen kleinen Festplatten-Tower mit einer Speicherkapazität von 3 TB zugeschickt. Auf dieses Speichermedium kann der Wissenschaftler dann seine Daten kopieren und an Google zurück zu senden - Google sorgt dann dafür dass die Daten innerhalb kürzester Zeit öffentlich verfügbar sind. Die dazugehörige Technik ist ebenfalls, wie der Trendalyzer, seit März 2007 vorhanden.
Der Starttermin für dieses Projekt lag in der letzten Woche, Google Research ist also längst überfällig und kann jeder Zeit an den Start gehen. Zum Start soll Google das Portal auch selbst schon mit interessanten Daten gefüttert haben - so soll etwa alleine vom Hubble-Teleskop Bildmaterial mit einer Größe von 120 TB (!) zur Verfügung stehen. Ich denke das Portal könnte, insbesondere in Verbindung mit dem Trendalyzer, ein schönes Spielzeug werden und die Hobby-Forschung fördern ;-)
P.S. Bisher handelt es sich, wie bei Google üblich, nur um ein Gerücht - aber ich halte es für sehr realistisch.
Hier noch eine Präsentation zu Google Research vom Mai 2007:
» Artikel bei Wired
» Artikel bei Pimm
[thx to: Richard]
Egal wieviele Features und Redesigns Google, Yahoo!, Live & co. ihren Suchmaschinen zuführen, im Grunde ist es immer dasselbe: Ein Suchschlitz, ein Button und die Anfrage wird in Stichwörtern eingegeben. Das war vor 10 Jahren so, ist heute so und wird auch in 10 Jahren noch so sein - zumindest prognostiziert dass Peter Norvig, Forschungsdirektor bei Google.
Wir glauben, dass es wichtiger ist, die richtigen Ergebnisse auszugeben, nicht die Schnittstelle zu verändern. Wir haben das vorher immer dem Nutzer aufgebürdet, ob er nun im Web, nach Bildern oder Videos suchen will. Nun versuchen wir, das für ihn zu lösen und die Ergebnisse zu präsentieren, die sinnvoll sindIn den letzten Jahren war immer wieder die Rede von in Entwicklung befindlichen Techniken die es ermöglichen sollten mit Suchmaschinen zu kommunizieren bzw. dass eine Frage in natürlicher Sprache eingegeben werden kann und von der Suchmaschine beantwortet wird. Wirklich viel hat man davon aber noch nicht gesehen, und die die es versucht haben haben kläglich versagt. Scheinbar hat auch Google diese vermeintliche Zukunftstechnik jetzt aufgegeben - oder warum äußert sich Peter so kritisch darüber? Norvig ist der Meinung dass die eigentliche Anfrage-Technik gegenwärtig perfekt ist und nicht weiter verbessert werden kann - die Hersteller sollten sich lieber auf die Verbesserung der Suchergebnisse konzentrieren. Als Forschungschef ist Peter Norvig natürlich sehr gut über Googles zukünftige Pläne informiert und dürfte mit seiner Prognose die grobe Richtung für Googles Suchmaschine in den nächsten Jahren vorgegeben haben: Mehr Konzentration auf Universal Search und eine eventuelle Design-Änderung der Suchergebnisse - Suchanfragen in natürlicher Sprache dürfen wir wohl eher nicht erwarten. » Interview bei Technology Review