Schlagwort: robots.txt
Google reagiert auf das Vorhaben von einigen Verlegern, die Google blockieren wollen, sodass sie nicht mehr über die Google News zu finden. Zum einen wird der Inhalt für die Google News nun über einen neuen Bot gecrawelt, zum anderen können die Publisher festlegen wie viele kostenpflichtige Artikel ein Nutzer pro Tag maximal anschauen kann.
Mit dem Programm "First Click Free" kann festgelegt werden, dass ein Nutzer bspw. maximal 5 Artikel via Google Search bzw. Google News anschauen kann, bevor er dafür beim Verleger bezahlen muss.
Wer nicht möchte, dass seine Artikel in den Google News laden, kann dies nun über die robots.txt festlegen. Google News wird ab sofort von von Googlebot-News gecrawelt. So lässt sich festlegen, dass bspw. das Archiv nicht aufgenommen werden darf oder die neusten Artikel nicht sofort in den News laden. Weitere Beispiele gibt es hier.
Der user agent lautet Googlebot-News.
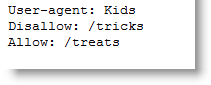
Dass sich Googler gelegentlich einen Scherz - vor allem am ersten April - erlauben, sollte bekannt sein. Daher darf man auch über den neusten Eintrag in die Google Robots.txt getrost lachen:
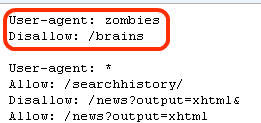 google.com/brains liefert übrigens eine 404-Fehlerseite.
» Google Robots.txt
google.com/brains liefert übrigens eine 404-Fehlerseite.
» Google Robots.txt
google.com/brains liefert übrigens eine 404-Fehlerseite.
» Google Robots.txt
 Bisher waren die Seiten von Google Profile nur eher sporadisch von Suchmaschinen indiziert worden - einfach aus dem Grund das sie nirgendwo öffentlich verlinkt sind, es sei denn der User verlinkt sich selbst irgendwo. In einigen Stunden wird sich das allerdings ändern, denn Google teilt allen Suchmaschinen nun per Sitemap die URLs von 150.000 öffentlichen Profilen mit.
Seit wenigen Stunden findet sich in Googles robots.txt ein Link zu einer Profiles Sitemap in dem wiederum 30 Textdateien verlinkt sind. Jeder dieser Textdateien enthält 5.000 URLs die allesamt auf gut gefüllte Profile verlinken. Es ist also nur noch eine Frage von Stunden bis die großen Suchmaschinen die Profile indiziert und gelistet haben.
Hervorgegangen ist das Google Profile damals aus Google Shared Stuff und wurde seitdem kontinuierlich erweitert und in verschiedene Dienste wie Maps, Reader und Knol integriert. Wirklich selbstständig war der Dienst bisher aber nicht, das wird sich nun ändern und das Profile wird quasi die Web-Visitenkarte hosted by Google.
Da die Visitenkarten direkt auf google.com gehostet werden, dürfte diese bei sehr vielen Namen jetzt direkt auf Platz 1 in den Suchergebnissen stehen. Ich denke Google hätte einige Wochen vor dieser Öffnung eine Möglichkeit anbieten sollen das Profil aus Suchmaschinen entfernen zu dürfen bzw. gar nicht erst listen lassen zu dürfen. Was haltet ihr von dieser direkten Verlinkung der Profile?
P.S. Es scheinen 150.000 Profile verlinkt zu sein. Hat jemand eine Ahnung ob diese Zahl realistisch ist oder ob es noch mehr Profile gibt? Ist eure Seite gelistet?
» Profile-Sitemaps
[ZDNet-Blog]
Bisher waren die Seiten von Google Profile nur eher sporadisch von Suchmaschinen indiziert worden - einfach aus dem Grund das sie nirgendwo öffentlich verlinkt sind, es sei denn der User verlinkt sich selbst irgendwo. In einigen Stunden wird sich das allerdings ändern, denn Google teilt allen Suchmaschinen nun per Sitemap die URLs von 150.000 öffentlichen Profilen mit.
Seit wenigen Stunden findet sich in Googles robots.txt ein Link zu einer Profiles Sitemap in dem wiederum 30 Textdateien verlinkt sind. Jeder dieser Textdateien enthält 5.000 URLs die allesamt auf gut gefüllte Profile verlinken. Es ist also nur noch eine Frage von Stunden bis die großen Suchmaschinen die Profile indiziert und gelistet haben.
Hervorgegangen ist das Google Profile damals aus Google Shared Stuff und wurde seitdem kontinuierlich erweitert und in verschiedene Dienste wie Maps, Reader und Knol integriert. Wirklich selbstständig war der Dienst bisher aber nicht, das wird sich nun ändern und das Profile wird quasi die Web-Visitenkarte hosted by Google.
Da die Visitenkarten direkt auf google.com gehostet werden, dürfte diese bei sehr vielen Namen jetzt direkt auf Platz 1 in den Suchergebnissen stehen. Ich denke Google hätte einige Wochen vor dieser Öffnung eine Möglichkeit anbieten sollen das Profil aus Suchmaschinen entfernen zu dürfen bzw. gar nicht erst listen lassen zu dürfen. Was haltet ihr von dieser direkten Verlinkung der Profile?
P.S. Es scheinen 150.000 Profile verlinkt zu sein. Hat jemand eine Ahnung ob diese Zahl realistisch ist oder ob es noch mehr Profile gibt? Ist eure Seite gelistet?
» Profile-Sitemaps
[ZDNet-Blog]
 Lange Zeit nicht mehr von Googles robots.txt gehört, aber jetzt gibt es endlich mal wieder einen neuen Eintrag der uns spekulieren lässt: Der Eintrag verweist auf google.com/MerchantSearchBeta und liefert - wen wundert es - mal wieder eine 404er Meldung zurück. Ich tippe auf eine Händler-Suche als Mix aus Google Maps, Product Search aka Froogle und vielleicht auch eine Wiederbelebung von Google Catalogs.
P.S. Ich glaube das wäre Googles erster Dienst der das Wort "Beta" schon in der URL enthält :-D
» robots.txt
[Google Blogoscoped Forum]
In Googles robots.txt ist mal wieder ein neuer Eintrag aufgetaucht. Worum es sich bei dem jetzt für Suchmaschinen gesperrten Ordner aclk handelt ist bisher noch nicht bekannt. Auch eine mögliche Abkürzung für irgendetwas ist bisher noch niemandem eingefallen. Interessant an der Sache ist, dass jeder beliebiger Unterordner aufgerufen werden kann und immer, genau wie das aclk-Verzeichnis selbst, eine komplett leere Seite zurück gibt.
[Blogoscoped-Forum]
Lange Zeit nicht mehr von Googles robots.txt gehört, aber jetzt gibt es endlich mal wieder einen neuen Eintrag der uns spekulieren lässt: Der Eintrag verweist auf google.com/MerchantSearchBeta und liefert - wen wundert es - mal wieder eine 404er Meldung zurück. Ich tippe auf eine Händler-Suche als Mix aus Google Maps, Product Search aka Froogle und vielleicht auch eine Wiederbelebung von Google Catalogs.
P.S. Ich glaube das wäre Googles erster Dienst der das Wort "Beta" schon in der URL enthält :-D
» robots.txt
[Google Blogoscoped Forum]
In Googles robots.txt ist mal wieder ein neuer Eintrag aufgetaucht. Worum es sich bei dem jetzt für Suchmaschinen gesperrten Ordner aclk handelt ist bisher noch nicht bekannt. Auch eine mögliche Abkürzung für irgendetwas ist bisher noch niemandem eingefallen. Interessant an der Sache ist, dass jeder beliebiger Unterordner aufgerufen werden kann und immer, genau wie das aclk-Verzeichnis selbst, eine komplett leere Seite zurück gibt.
[Blogoscoped-Forum]