Google Docs: Verbesserte Texterkennung (OCR) erkennt jetzt mehr als 200 Sprachen

Schon seit längerer Zeit bietet das Google Drive im Zusammenspiel mit Google Docs eine automatische Texterkennung an, die vor allem zum Einscannen von Dokumenten konzipiert ist. Diese Funktion steht sowohl auf dem Desktop als auch am Smartphone zur Verfügung und wurde nun noch weiter verbessert: Ab sofort unterstützt die Texterkennung (OCR) über 200 Sprachen und arbeitet nun noch einmal deutlich intelligenter. Die Erkennungsrate wurde erhöht und auch die Wahl der Sprache ist nun nicht mehr nötig.
Schon seit über fünf Jahren unterstützt Google Docs die automatische Umwandlung von eingescannten Dokumenten in Text. Was anfangs noch sehr wacklig funktioniert hat, und sehr viele händische Korrekturen benötigte, wurde im Laufe der Jahre immer weiter verbessert – und jetzt hat das Research-Team vielleicht den entscheidenden Sprung gemacht. Durch neue Technologien konnte sowohl die Erkennungsrate als auch die Anzahl der unterstützten Zahlen weiter gesteigert werden.
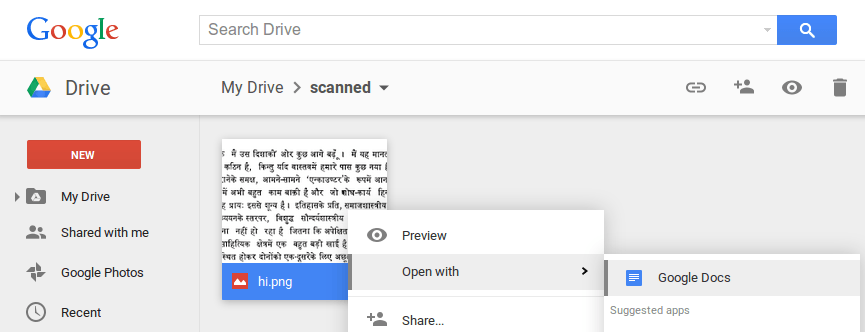
Ab sofort unterstützt die OCR-Funktion mehr als 200 Sprachen, und damit wohl so ziemlich jede die dem System jemals unterkommen dürfte. Um die Funktion zu nutzen benötigt man nur wenige Schritte: Einfach ein Bild mit Textinhalt in das Drive hochladen und dann im Kontextmenü „Öffne mit“ -> „Google Docs“ auswählen. Anschließend kann die Ladezeit einige Sekunden in Anspruch nehmen – je nach der Größe des Textes. Jetzt öffnet sich das Dokument mit dem Original-Bild und anschließend der eingescannte Text. Dieser ist dann genau so formatiert wie das Original – inklusive der verwendeten Schriftart. Alternativ kann auch einfach das Dokument mit der Drive-App fotografiert werden und wird dann automatisch umgewandelt.
Um diese mittlerweile doch sehr hohe Qualität zu erreichen, hat Google das dahinter liegende System geändert: Statt wie bisher jeden Buchstaben oder jedes Wort einzeln zu behandeln, wird nun der gesamte Satz behandelt, so dass Fehler bei der OCR-Erkennung einfacher ausgeglichen werden können. Das ganze System basiert auf Hidden Markov Models und wird so auch bei der Spracherkennung eingesetzt – ohne diese wäre eine so hohe Erkennungsrate wie wir sie heute kennen sonst nicht möglich. Auch bei der kürzlich veröffentlichten Handwriting-App kommt diese Technologie zum Einsatz.
Um das ganze System noch einfacher zu gestalten wird nun auch die Sprache automatisch erkannt, bisher musste diese in einigen Fällen noch händisch ausgewählt werden. Aktuell funktioniert das ganze dennoch nur bei Dokumenten mit einer hohen Auflösung und einer klaren Schärfe. Sinkt die Qualität, sinkt gleichzeitig auch die Erkennungsrate – aber das ist ja beim Menschen auch nicht viel anders. In Zukunft möchte man das System aber auch dahingehend trainieren, auch schlechtere Qualitäten zuverlässig zu erkennen – Vielleicht eines Tages sogar besser als der Mensch.
» Ankündigung im Research-Blog
GoogleWatchBlog bei Google News abonnieren | GoogleWatchBlog-Newsletter
Teile diesen Artikel:





Man sollte darauf hinweisen, das bei der Handwriting App vermutlich keine OCR gemacht wird (als Entwickler des Einzelsymbolerkenners write-math.com kenne ich mich in dem Gebiet ein bisschen aus). Vermutlich wird sog. „online-information“, also die Information wie das Zeichen geschrieben wurde (Strichrichtung, Geschwindigkeit, Reihenfolge der Striche) verwendet.