Beim Hochladen von Dokumenten zu Google Docs kann man ab sofort wählen, ob Google versuchen soll Texte zu erkennen und daraus ein Dokument zu machen.
Die Texterkennung ist natürlich noch nicht ganz ausgereift und so werden viele Zeichen falsch erkannt. Aus einem Ü wird mal û oder ú.
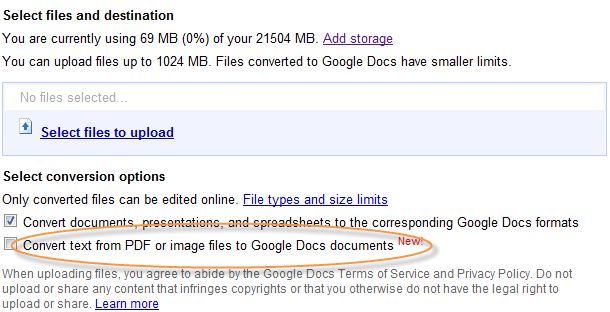
Aus dem Screenshot (rechts) machte Google folgendes:
Select files and destination You are currently using 69 MB (0%) of your21504 ME Add storage You can upload tiles up to ‘|024 MB. Files converted to Google Docs have smaller limits. Select conversion options Only converted ñles can be edited online. File tyges and size limits
Beim Texten, die in einer etwas ausgefalleneren Schrift waren, gab es deutliche Probleme. Arial, Times und Tahoma lieferten bei unseren Tests sehr gute Ergebnisse.